Incremental Ensemble Classifier Addressing Dynamic, Evolving, and Non-Stationary Streams.
B. Parker, L. Khan, A. Bifet. ICDM-IClaNov Workshop. 2014.
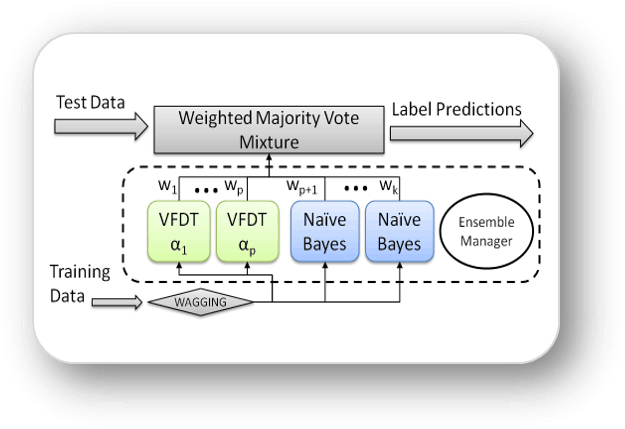
While streaming data is often placed into the context of "Big Data" (or more specifically "Fast Data") wherein one-pass algorithms are used, true data streams offer additional hurdles due to their dynamic, evolving, and non-stationary nature. In this paper, we describe a new approach to using ensembles for stream classification. While the core method is straightforward, it is specifically designed to adapt quickly with very little overhead to the dynamic and evolving nature of data streams generated from non-stationary functions. Our method, M3 , is based on a weighted majority ensemble of heterogeneous model types where model weights are updated on-line using Reinforcement Learning techniques.
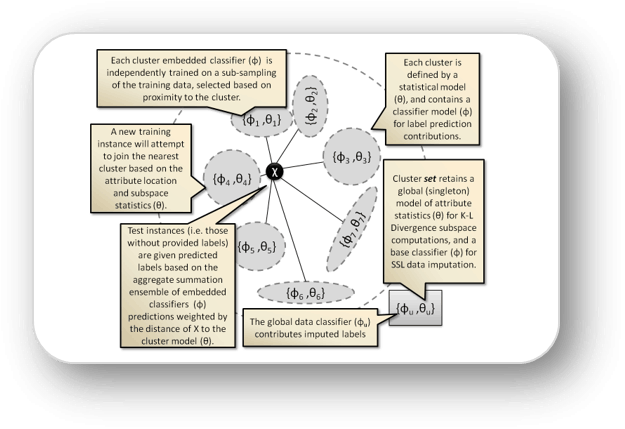
SLUICEBOX: Semi-supervised Learning for Label Prediction with Concept Evolution and Tracking in Non-Stationary Data Streams,
B. Parker. Dissertation, 2014.
The SluiceBox method described in this dissertation
aims to adapt to novel classes, feature evolution, and concept drift while predicting
data instance labels and adhering to the constraints of continuous data streams.
The research presented here details the challenges found in data stream mining,
and explores the theoretical requirements for detecting emerging novel classes. It also
presents a framework for data stream experimentation as an extension of the Waikato
University MOA framework. Finally, the theoretical observations are tested within
the framework using an implementation of a new online stream classifier method
known as SluiceBox.
Detecting and Tracking Concept Class Drift and Emergence in Non-Stationary Fast Data Streams
B. Parker, L. Khan. In Proceedings of the 20th AAAI Conference on Artificial Intelligence, 2015.
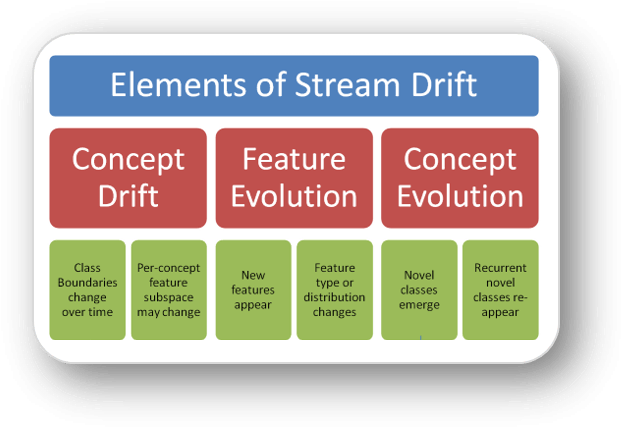
As the proliferation of constant data feeds increases from social media, embedded sensors, and other sources, the capability to provide predictive concept labels to these data streams will become ever more important and lucrative. However, the dynamic, non-stationary nature, and effectively infinite length of data streams pose additional challenges for stream data mining algorithms. The sparse quantity of training data also limits the use of algorithms that are heavily dependent on supervised training. To address all these issues, we propose an incremental semi-supervised method that provides general concept class label predictions, but it also tracks concept clusters within the feature space using an innovative new online clustering algorithm.
Evolving Data Stream Classification with MapReduce.
A. Haque, B. Parker, L. Khan, B. Thuraisingham. IEEE 7th International Conference on Cloud Computing. 2014.
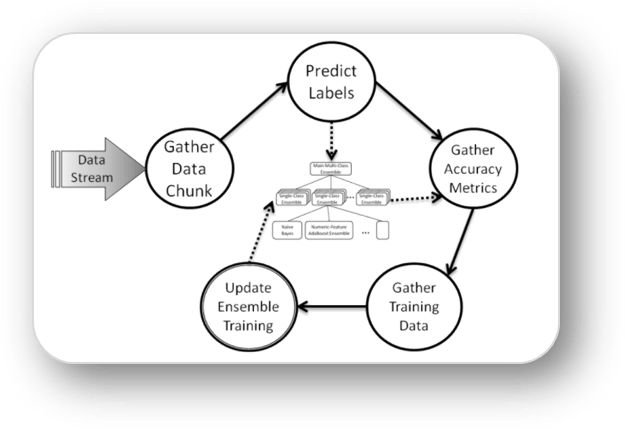
In our current work, we have designed a multi-tiered ensemble based method HSMiner to address aforementioned challenges to label instances in an evolving Big Data Stream. However, this method requires building large number of AdaBoost ensembles for each of the numeric features after receiving each new data chunk which is very costly. Thus, HSMiner may face scalability issue in case of classifying Big Data Stream. To address this problem, we propose three approaches to build these large number of AdaBoost ensembles using MapReduce based parallelism.
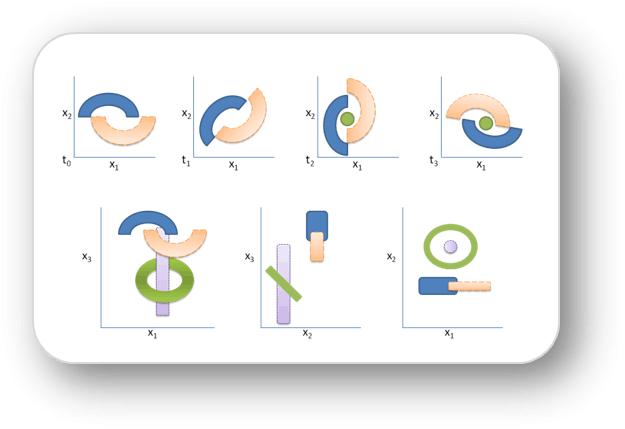
Rapidly Labeling and Tracking Dynamically Evolving Concepts in Data Streams
B. Parker, L. Khan. In Proceedings of the 2013 IEEE 13th International Conference. 2013, pp. 1161-1164. on Data Mining Workshops, ICDMW `13, Dallas, TX, USA.
Mining streaming data becomes challenging when using a piece-wise or online approach, however, due to concept drift and feature evolution. As the stream progresses, features may be added, removed, or change in the range of possible values, which is known as feature evolution. The defining concepts for a label or class may also migrate over the span of the data stream. Novel classes that were not known a priori can also appear within the data stream. Our solution consists of an adaptive supervised ensemble for predicting instance labels, and a stream clustering approach to monitor concept defining characteristics and novel class development without regard to label (i.e. unsupervised).
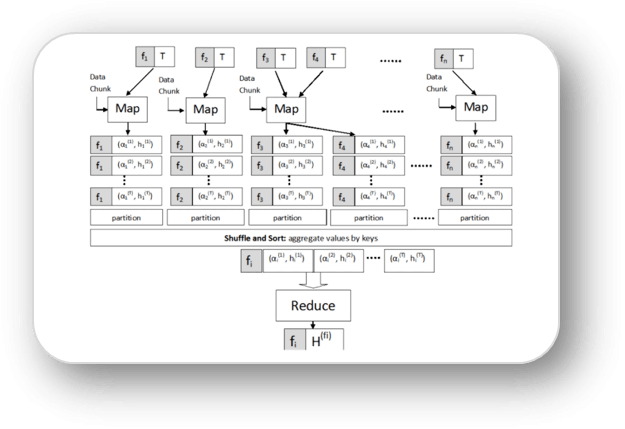
Labeling Instances in Evolving Data Streams with MapReduce
A. Haque, B. Parker, and L. Khan. IEEE Big Data Congress. Santa Clara, CA, 2013.
In our current work we have proposed a multi-tiered ensemble based fast and robust method, which rapidly learns the concepts in a data stream, predicts labels for new data with strong accuracy, and agilely tracks the dynamic changes in the evolving concepts and feature space. Bottleneck of our current work is, it needs to build ADABOOST ensemble for each numeric feature. This can face scalability issue as number of features can be very large at times in data stream. In this paper we propose a method to parallelize the independent parts of that work using MapReduce framework. This increases scalability and achieve a significant speedup without compromising classification accuracy.
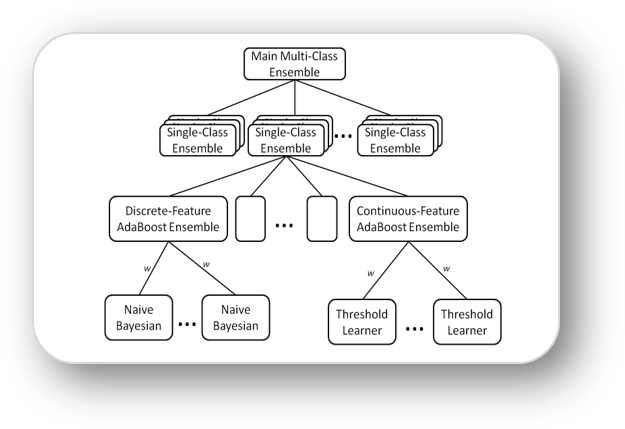
Novel Class Detection and Feature Tracking via a Tiered Ensemble Approach for Stream Mining
B. Parker, A. Mustafa, and L. Khan. In Proceedings of the 2012 IEEE 24th International Conference on Tools with Artificial Intelligence, ICTAI '12, pages 1171. 2012.
Static data mining assumptions with regard to features and labels often fail the streaming context. Features evolve, concepts drift, and novel classes are introduced. Our approach -- named HSMiner (Hierarchical Stream Miner) -- takes a hierarchical decomposition approach to the ensemble classifier concept. By breaking the classification problem into tiers, we can better prune the irrelevant features and counter individual classification error through weighted voting and boosting. In addition, the atomic decomposition of feature inputs enables straightforward mapping to distributing the ensemble among resources in the network.
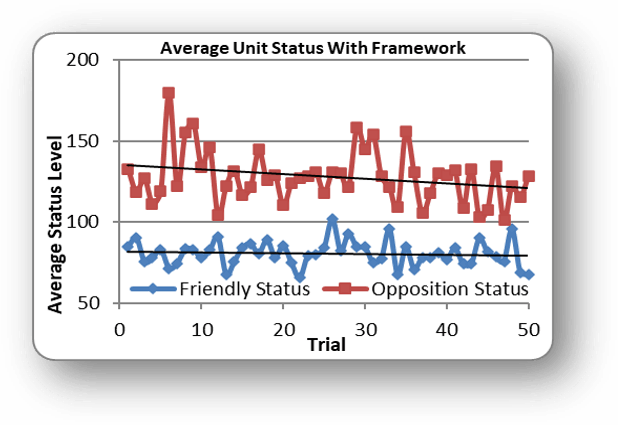
UAS SENSOR AUTONOMY ACHIEVED VIA MARKET-BASED OPTIMIZATION METHODS
B. Parker. 29th DASC, 2010.
As ISR sensors proliferate in theater, the autonomous and dynamic control of those sensors, especially those on board unmanned aircraft systems, will become a necessity as personnel and resource constraints drive the shift in operator control from manual tasking and prioritization to system supervision. This paper explores the experimentation, analysis, and viability of a decentralized, auction-less market-based algorithm to fulfill such a need.

CLUE: CLUster Evaluation Tool
B. Parker. Master's Thesis, 2006.
Modern high performance computing is dependent on parallel processing systems. Most current benchmarks reveal only the high level computational throughput metrics, which may be sufficient for single processor systems, but can lead to misrepresentation of true system capability for parallel systems. A new benchmark is therefore proposed. CLUE (Cluster Evaluator) uses a cellular automata algorithm to evaluate the scalability of parallel processing machines. The benchmark also uses algorithmic variations to evaluate individual system components' impact on the overall serial fraction and efficiency.
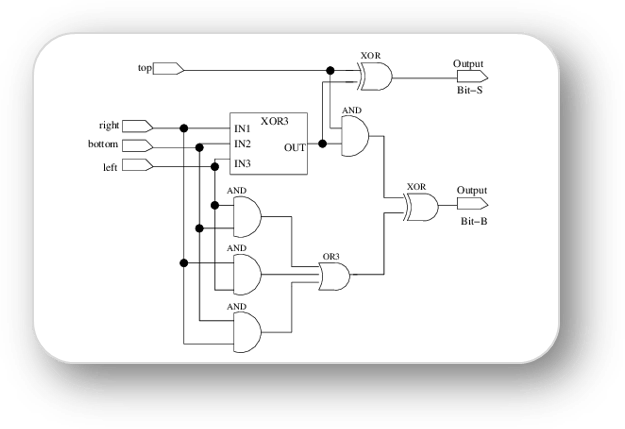
A High-Performance ASIC for Cellular Automata (CA) Applications
C.A. Kincaid, S.P. Mohanty, A.R. Mikler, E. Kougianos, B. Parker. 9th International Conference on Information Technology, 2006.
CA are useful tools in modeling and simulation. However, the more complex a CA is, the longer it takes to run in typical environments. A dedicated CA machine solves this problem by allowing all cells to be computed in parallel. In this paper we present simple yet useful hardware (FPGA) that can perform the required computations in constant time complexity.